|
|
本文仍处于草稿阶段,有些细节还没补充上,最近有点事。 本篇主要讲得是手游CPU优化,属于Unity中级水平篇,不涉及GPU、Shader渲染细节的优化。
优化的3种类型
根据测试目标机型的性能指标,自动为其设置合适的参数。
如:检测到低端手机就不开阴影,设置为低帧率。
通过一系列取巧(符合一定规律)或作假的手段,达到性能消耗少的同时,效果和原来几乎一致。
如:使用精灵图集、List.Clear代替New List,防止出现GC。
增加一项指标,减少另一项(超标)指标。
如:静态合批就是增加内存,减少DrawCall。
优化目的
- 稳定(防止卡顿)
- 流畅(高帧率运行、切换场景流畅、战斗流畅等)
- 低耗低热(提高用户体验)
- 低流量(减少服务器压力,花更少的钱)
优化指标
手游优化指标建议(2021年)
- DrawCall:(安卓)100以内,峰值150以内;(iphoneX以下)70以内,峰值是100
- Verts(三角顶点数):200K以内
- Tris(面数):400K以内
- SkinMeshRender:50以内(ECS除外)
- RigidBody:50以内
- Collider:100以内
设置界面一般控制的参数
- 整体设置推荐组(高、中、低、自定义)
- 帧率(30、45、60)
- 抗锯齿(无、2X、4X)
- 后处理效果等级(关、普通、高级)
- 特效效果等级(普通、高级)
- 纹理等级(普通、中等、高级)
适配机型要求
- 高级:在保证所有设计和美术效果的情况下,适当调高一些参数(帧率、描边、抗锯齿、后处理效果等级等)
- 中级:保证展示出项目的所有设计和美术效果。
- 低级:只保证功能,不保证美术效果。
- 更低级:请用户换手机。
<hr/>性能分析
两种比较常用的性能分析网站
UWA是很老牌的性能优化服务商,做的时间久,经验丰富。除了本地测试产品之外,他们也有云端测试产品和驻场服务。
UWA是提交项目,由侑虎团队进行托管测试,而UPR是提供工具让项目自己测试。 玩游戏手机发烫的主要原因
- 内存占用长时间超过标准值(使用RenderTexture未卸载、一口气加载所有贴图资源、频繁GC等)
- CPU占用高(DrawCall)
- GPU占用高(后处理、抗锯齿)
- 高帧率(代码Update消耗占比高)
- 手机本身原因(充着电玩、硬件出现问题、手机本身性能不好等)
推荐文章
- 《天谕》手游分析报告(下)-性能优化分析 - 放牛的星星的文章 - 知乎
- Unity基础教程系列(新)(四)——测量性能(MS and FPS)
<hr/>CPU优化
合批
DrawCall高为什么会有性能问题?
渲染流水线问题,如果有大量DrawCall(CPU提交数据多),GPU就会处于空闲状态。
关于静态批处理/动态批处理/GPU Instancing /SRP Batcher的详细剖析 - SamUncle的文章 - 知乎
- 静态合批:相同材质球(减少Dc,但增加内存,对LOD不友好,非静态物体无效)
- MeshBaker:类似静态合批,但它是手动的,静态合批是自动的。
- 动态合批:相同材质球(要求苛刻,有很多限制,一般用于UI)
- GPUInstance:相同材质球、相同Mesh的物体才生效(一次绘制调用最多是500个实例)
- SRP合批:Shader中变体一致,就可以启用SRP Batcher加速(本质并不会降低Draw Calls的数量,它只会降低Draw Calls之间的GPU设置成本)
阴影
- Build-In渲染管线开启阴影性能很差。
- 面片阴影(即原来物体显示模式勾选为ShaderOnly),可以被合批。
- 如果完全是平地,使用平面阴影投射方案性能好,效果好(无论是哪种渲染管线都可以使用)。
- 投影(Unity的投影阴影 - 冰心夜雨的文章 - 知乎) 。
抗锯齿与后处理
- 错误的使用抗锯齿和后处理会导致 GPU和CPU 消耗攀升
物理优化
代码效率
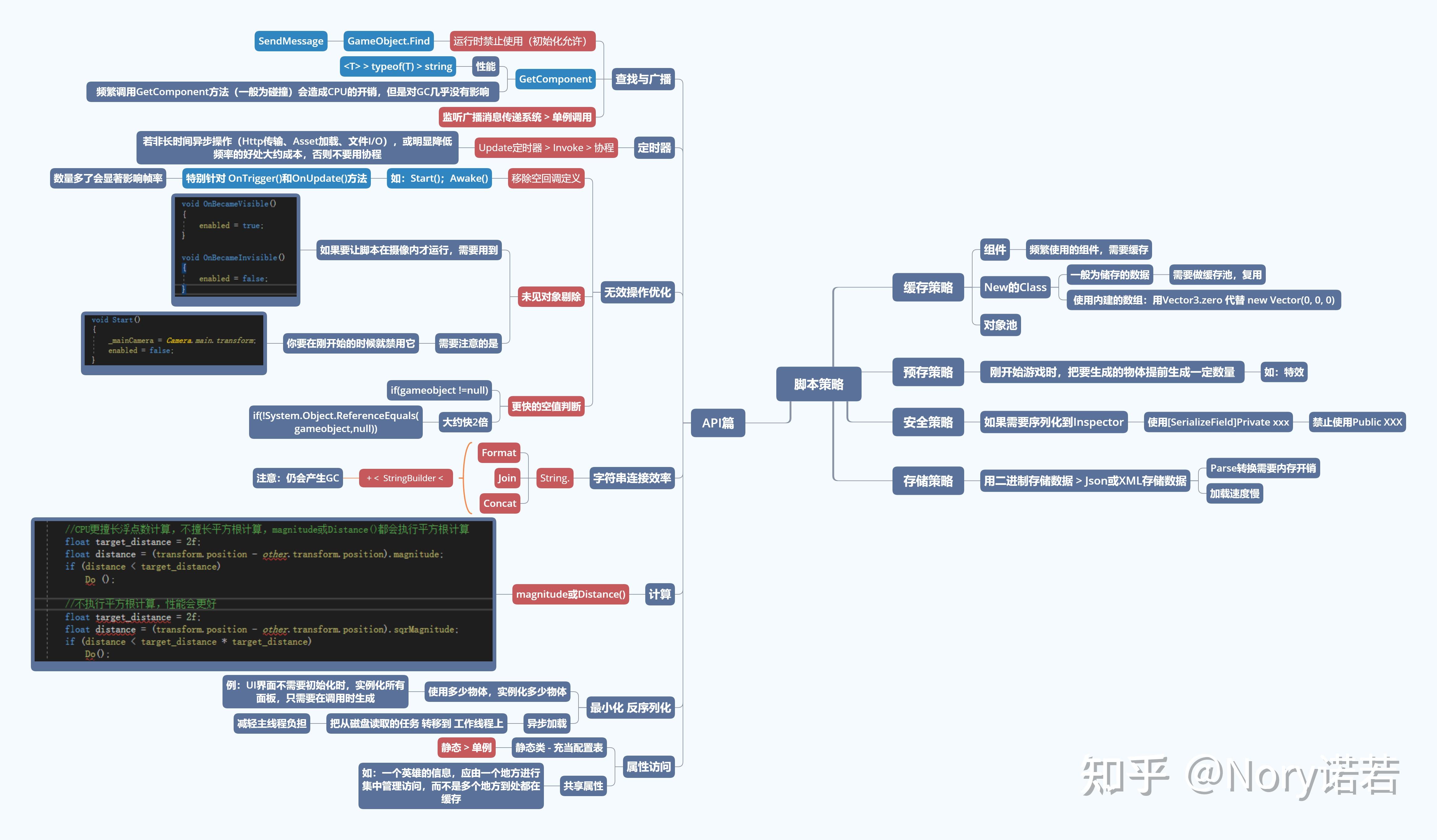
粒子特效篇
- 同一节点下的粒子系统们【含有不同材质】,需要给特效设置RenderQueue。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
<hr/>内存优化
UWA内存标准(2017年)
- 总内存: 150 MB
- 纹理资源: 50 MB -> Assets - Texture2D 和 Assets(和Not Saved) - RenderTexture
- 网格资源: 20 MB -> Assets - Mesh
- 动画片段: 15 MB -> Assets - AnimationClip
- 音频片段: 15 MB -> Assets - FMOD
- Mono堆内存: 40 MB -> Simple - Mono
- 其他: 10 MB(不含字体)
ProFiler查看内存
GC
- 少用协程(开启一个协程,至少分配37B的内存,实例(21B),Enumerator(16B))
- 避免运行时New
- 避免字符串+连接:建议使用stringBuilder或String.Format
- 少用obj.name(39B)/obj.tag:都会返回新的字符串
- 集合Clear代替 New集合
- 使用缓存思想:对象池、公用对象
- 避免装箱
- 用List代替ArrayList
- unity5.5(2017)以下版本,避免Foreach(会把代码转成IL,有装箱操作)
- 谨慎在项目中使用不知细节的插件
加载模块
《天谕》手游分析报告(下)-性能优化分析 - 放牛的星星的文章 - 知乎 按需加载:只加载用到的资源,卸载不用的资源。
- 分层(不同物件有不同的视距)
- 分块(九宫格加载可视物体)
- 流式(异步动态加载卸载周围的资源)
- LOD
导入格式规范
分类文件,根据文件夹路径,使用代码在导入时自动设置导入文件的格式。
- 贴图:TextureImportSetting
- 模型:FbxImportSetting
动画文件
Unity+模型/动画的优化方案 - 喵小逗的文章 - 知乎
- 不勾选Read/Write
- Model如果是动画文件,Avatar Definiton = FromOther,
- Model如果是皮肤文件,(如果需要随骨骼动,那么勾选出来)
- 不勾选导入材质
- 优化计算精度
《天谕》手游分析报告(下)-性能优化分析 - 放牛的星星的文章 - 知乎 动画按需加载
- AnimatorController会把动画一次性全部加载进来,如果动画过多,则会耗时过高,卡顿,内存过大。可以使用PlayableController和PlayableGraph来控制
- 动画可以按需异步加载,基于Playable API实现StateMachine/BlendTree/Layer
- 可全局缓存和复用,从AnimatorController导出(兼容,易用,转换快)
纹理
1. 纹理贴图参数
- Read/Write:可以在运行时进行贴图合并操作,但双倍内存消耗,通常需要关闭。
- Mipmap:生成多级LOD图片,在运行时根据摄像机距离自动切换图片,会将纹理内存提升1.33倍。
- SRGB(通用色彩标准):和渲染空间有关,Mask纹理、噪声图等需要取消。
- MaxSize:越高越清晰,内存占用量也会增加。(512X512:1024X1204:2048X2048 - 1 :4:16)
2. 纹理贴图格式
Unity2018以下,IOS平台建议使用PVRTC压缩,Android建议使用ETC1压缩
- 美术效果排序(从高到低):RGBA32 > RGBA16 > ETC1/ETC2/PVRTC
- 性能优化排序(从高到低):ETC1/ETC2/PVRTC > RGBA16 > RGBA32
Unity2018以上,IOS和安卓均建议使用ASTC
ASTC纹理压缩格式详解 - Ssiya的文章 - 知乎
ASTC格式支持RGBA,且适用于2的幂次方长宽等比尺寸和无尺寸要求的NPOT(非2的幂次方)纹理。 无Alpha通道(建议)
- 【正常贴图】正常质量:ASTC 8x8;高质量:ASTC 6x6(如:面部、场景地面)
- 【法线贴图】正常质量:ASTC 5x5;高质量:ASTC 4x4
有Alpha通道(建议)(带Alpha通道的贴图压缩质量会下降)
- 【正常贴图】正常质量:ASTC 5x5;高质量:ASTC 4x4(如:特效)
3. 纹理或纹理图集优化原则
- 九宫格图:最小化处理
- 大图(背景图、骨骼动画图、人物原画),不打入图集
- 图片导出为:能倍4整除的尺寸(如:400x800)
4. 分治纹理图集
- 如果图片全局通用:放入常驻内存图集
- 如果图片很小,出现在多个UI:每个UI的图集都打入这个图片,并且对应UI使用自己的图集
- 如果图片很大,出现在多个UI:按需加载,当需要用到的UI启动时,再对应UI图集到载入内存
音频资源
Unity基础之音频资源设置
- 经常播放、短音频:&#34;Decompress On Load&#34;和&#34;PCM&#34;
- 经常播放、中等大小音频:&#34;Compressed In Memory&#34;和&#34;ADPCM&#34;
- 很少播放、短音频:&#34;Compressed In Memory&#34;和&#34;PCM&#34;
- 很少播放、中等大小音频:&#34;Compressed In Memory&#34;和&#34;Vorbis - Quality 70左右&#34;(最低内存占用)
- 长音频:&#34;Vorbis - Quality 70左右&#34;和&#34;Streaming&#34;(或 &#34;Compressed In Memory&#34;:磁盘I/O操作被替换成内存的消耗)
模型资源
数据表大小优化
《天谕》手游分析报告(下)-性能优化分析 - 放牛的星星的文章 - 知乎
- 数字压缩类似protobuf的varint编码进行优化
- 集中提取字符串并去重
- 提取表格公共(相似)部分
- 读取速度和易用性
- 适当添加缓存
- 返回userdata,通过修改metatable,保持对外的一致性
- readonly(Lua无法实现,但是C++简单,不过新版本Lua好像有了)
ShaderLab内存优化
《天谕》手游分析报告(下)-性能优化分析 - 放牛的星星的文章 - 知乎
- 变种过多:合理使用#pragma multi_compile 和 #pragma shader_feature
- 合并变种: #pragma multi_compile A B C
- 关闭内置变种:#pragma skip_variants,如:nodynlightmap,nofog,noambient,nolppv等
- 禁用内置shader:诸如Standard Shader等。
- 使用ShaderVariantCollection:统一管理
- OnProcessShader剔除变体:2018.2版本之后可以用
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|


 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2022-1-18 09:08
发表于 2022-1-18 09:08
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡