|
|
1 优化技术简介
优化技术基于不同的理论有很多种,在本次 Lecture 中主要讨论一阶优化算法、二阶优化算法。
对于凸优化来说,任何局部最优解即为全局最优解。用贪婪算法或梯度下降法都能收敛到全局最优解,而非凸优化问题则可能存在无数个局部最优点,可以看出有非常多的极值点,有极大值也有极小值。除了极大极小值,还有一类值为鞍点(saddle point),简单来说,它就是在某一些方向梯度下降,另一些方向梯度上升,形状似马鞍,如下图所示。对于深度学习模型的优化来说,鞍点比局部极大值点或者极小值点带来的问题更加严重。
Some Popular Optimization Techniques
- Gradient Descent(GD)
- Adagrad, Adam, Adadelta
- Newton’s method, Quasi-Newton’s method
- BFGS, L-BFGS
- ADMM
- Coordinate Descent
- Mirror Descent
- Projected Gradient Descent
- MCMC
- ……
在机器学习中,有很多的问题并没有解析形式的解,或者有解析形式的解但是计算量很大。对于此类问题,通常我们会选择采用一种迭代的优化方法进行求解。目前常用的优化方法分为一阶和二阶,这里的阶对应导数,一阶方法只需要一阶导数,二阶方法需要二阶导数。常用的一阶算法有梯度下降法及其各类变种;常用的二阶算法有牛顿法等。
2 梯度下降法 (Gradient Descent Algorithm)
想象你在一个山峰上,在不考虑其他因素的情况下,你要如何行走才能最快的下到山脚?当然是选择最陡峭的地方,这也是梯度下降法的核心思想:它通过每次在当前梯度方向(最陡峭的方向)向前“迈”一步,来逐渐逼近函数的最小值。
在第 n 次迭代中,参数 \theta_n=\theta_{n-1}+\Delta\theta ,我们将损失函数在 \theta_{n-1} 处进行一阶泰勒展开:
L(\theta_n)=L(\theta_{n-1}+\Delta\theta)\approx L(\theta_{n-1})+L^{'}(\theta_{n-1})\Delta\theta
为了使 L(\theta_n)\lt L(\theta_{n-1}) ,可取 \Delta\theta=-\alpha L^{'}(\theta_{n-1}) ,这里的 \alpha 称之为学习率(learning rate),于是得到以下梯度下降的迭代公式:
\theta_n:=\theta_{n-1}-\alpha L^{'}(\theta_{n-1})
梯度下降法根据每次求解损失函数 L 带入的样本数,可以分为:全量梯度下降(计算所有样本的损失)、批量梯度下降(每次计算一个 batch 样本的损失)、随机梯度下降(每次随机选取一个样本计算损失)。
注:现在所说的 SGD(随机梯度下降)多指Mini-batch-Gradient-Descent(批量梯度下降),后文用 g_n 来代替 L^{'}(\theta_{n}) 进行表示。
Dark art of learning rate
学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值,合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
如上图所示:当学习率设置的过小时,收敛过程将变得十分缓慢;而当学习率设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。
如何调整学习率
- 离散下降 (discrete staircase):对于深度学习来说,每 t 轮学习,学习率减半。对于监督学习来说,初始设置一个较大的学习率,然后随着迭代次数的增加,减小学习率。
- 指数衰减 (exponential decay):对于深度学习来说,学习率按训练轮数增长指数差值递减。例如:
- \alpha = 0.95^{epoch\_num} \cdot \alpha_0 \\ 或者 \\ \alpha = \frac{k}{\sqrt {epoch\_num}} \\ 其中epoch_num为当前epoch的迭代轮数,第二种方法会引入另一个超参k。
- 分数衰减 (1/t decay):对于深度学习来说,学习率按照公式 \alpha = \frac{\alpha}{1+ {decayRate} * {epochNum}} 变化, decayRate控制减缓幅度。
How to analyze the complexity
具体可移步:
3 自适应梯度法 (Adaptive Gradient, AdaGrad)
AdaGrad, a variant of gradient descent
- Set the step-size adaptively for every feature.
- Set a small learning rate for features that have large gradients, and a large learning rate for features with small gradients.
自适应梯度法。它通过记录每次迭代过程中的前进方向和距离,从而使得针对不同问题,有一套自适应调整学习率的方法:
\Delta\theta_n = \frac{1}{\sqrt{\sum_{i=1}^{n-1}g_{i}+\epsilon}} g_{n-1} \\ \theta_n:=\theta_{n-1}-\alpha\Delta\theta_n
随着迭代的增加学习率是在逐渐变小的,这在“直观上”是正确的:当越接近最优解时,函数的“坡度”会越平缓,我们也必须走得更慢来保证不会穿过最优解。这个变小的幅度只跟当前问题的函数梯度有关, \epsilon 是为了防止0除,一般取1e-7。
AdaGrad 解决了 SGD 中学习率不能自适应调整的问题。但是,学习率单调递减,在迭代后期可能导致学习率变得特别小而导致收敛及其缓慢;同时还需要手动设置初始α值。
The problem with 1st order gradient methods
梯度下降算法的缺陷在于停滞区、鞍点、极小值的存在:
- 停滞区:函数在某一段区域,梯度很小,且范围很大,梯度值小于更新条件,此时算法可能会停止迭代。
- 鞍点:函数会出现存在梯度为0的临界点,但该点不是最小点也不是最大点。
- 极小值:靠近极小值时收敛速度减慢,求解需要很多次的迭代;寻找到极小值时会使算法停止迭代,从而得到不准确的结果,陷入局部最优解的情况。
以上是一阶优化算法存在的缺陷,因此引入二阶优化算法进行改进。
4 牛顿法 (2nd order approximation)
仍旧想象你在一个山峰上,想找一条最短的路径走到一个山的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步;而牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑走了一步之后的坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。
Advantage of Newton's Method
- Much fewer iterations compared to gradient descent
- No need to set learning rate
Looks very promising !
牛顿法使用了一阶导信息,同时还利用了二阶导来更新参数,其形式化的公式如下:
\theta_n:=\theta_{n-1}-\alpha\frac{L^{'}_{n-1}}{L^{''}_{n-1}}
回顾之前的 \theta_n=\theta_{n-1}+\Delta\theta ,我们将损失函数在 \theta_{n-1} 处进行二阶泰勒展开:
L(\theta_n)=L(\theta_{n-1}+\Delta\theta)\approx L(\theta_{n-1})+L^{'}(\theta_{n-1})\Delta\theta+\frac{L^{''}(\theta_{n-1})\Delta\theta^2}{2}
要使 L(\theta_n)\lt L(\theta_{n-1}) ,我们需要极小化 L^{'}(\theta_{n-1})\Delta\theta+\frac{L^{''}(\theta_{n-1})\Delta\theta^2}{2} ,对其求导,令导数为零,可以得到:
\Delta\theta = -\frac{L^{'}_{n-1}}{L^{''}_{n-1}}
也即牛顿法的迭代公式,拓展到高维数据,二阶导变为Hession矩阵,上式变为:
\Delta\theta = -H^{-1}L^{'}_{n-1}
直观上,我们可以这样理解:我们要求一个函数的极值,假设只有一个全局最优值,我们需要求得其导数为0的地方,我们把下图想成是损失函数的导数的图像 f(x) ,那么:
k=\tan \theta = f'(x_0)=\frac{f(x_0)}{x_0-x_1}\rightarrow x_1= x_0 - \frac{f(x_0)}{f'(x_0)}
我们一直这样做切线,最终 x_n 将逼近与 f'(x) 的0点,对于原函数而言,即 \Delta\theta = -\frac{L^{'}_{n-1}}{L^{''}_{n-1}} 。
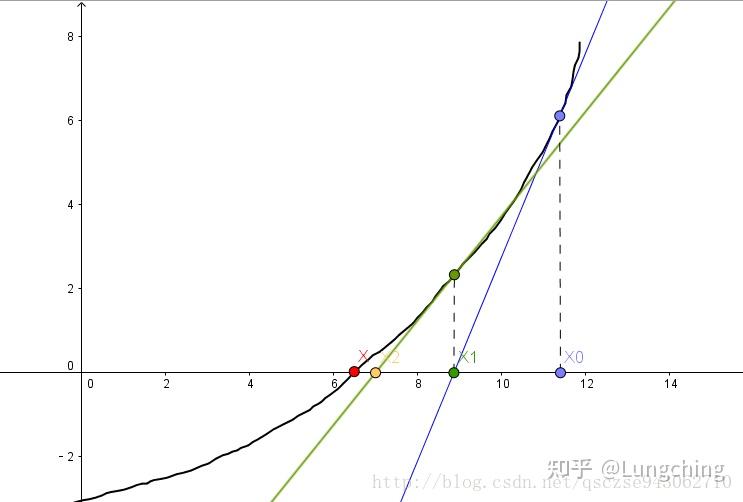
牛顿法具有二阶收敛性,每一轮迭代会让误差的数量级呈平方衰减,即在某一迭代中误差的数量级为0.01,则下一次迭代误差为0.0001,再下一次为0.00000001;收敛速度快,但是大规模数据时,Hession 矩阵的计算与存储将是性能的瓶颈所在。为此提出了一些算法,用来近似逼近这个 Hession 矩阵,最著名的有优于 BFGS(拟牛顿法之一)的 L-BFGS ,可适用于并行计算从而大大提高效率。
- 优点:二阶收敛,收敛速度快。
- 缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
5 拟牛顿法(Quasi-Newton Methods)
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的 Hessian 矩阵的逆矩阵的缺陷,使用正定矩阵来近似 Hessian 矩阵的逆,从而简化了运算的复杂度。
拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题;另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束、约束和大规模的优化问题。
具体可移步:
6 投影梯度下降 (Projected Gradient Descent, PGD)
投影梯度法(Projected Gradient Descent,简称 PGD)是求解带有简单约束的连续优化算法,主要是求解\min_{x\in S\subset\mathbb{R}^d}f(x),其中S是凸集。它的基本想法是先沿着下降方向走一步,再判断是否在可行域里,,具体迭代公式如下:
y^{k+1}=x^{k}-\alpha_k\nabla f(x^{k})\tag{下降}
x^{k+1}\in\arg\min_{x\in S}\|x-y^{k+1}\|^2_2\tag{投影}
投影保证了每次产生的 x^{k+1} 都在可行域中,而且向凸集的投影是唯一的。
它也是一种不动点迭代 ,也就是说下一步迭代只与当前步的迭代点有关,与其他迭代点无关:x^{k+1}=\arg\min_{y\in S}\|y-(x^k-\alpha_k \nabla f(x^k))\|^2_2=\mathbb{P}_{S}(x^k-\alpha_k \nabla f(x^k))。
在下降步里,没有必要非梯度下降不可,将其替换为牛顿法,就得到了投影牛顿法:
x^{k+1}=\mathbb{P}_{x\in S}(x^k-\alpha_k H_k^{-1}\nabla f(x^k)) ; 在投影步里,选择哪种范数或距离,也应该以便于计算为准则。镜像梯度,就是以 Bregman散度替换 \|\cdot\|_2^2 ,在某些情况下理论上比欧几里得范数的平方要好,比如镜像梯度法(mirror gradient method)。
结合两者的优点, 可以得到一种广义投影梯度法:
x^{k+1}=\arg\min_{x\in S}D_h(x, x^k-\alpha_kH_k^{-1}\nabla f(x^{k})) 。 以上摘自 基于梯度的优化:投影梯度和牛顿法,更多关于投影梯度的理论与算法,可看何炳生教授的讲义:
PGD 本身最适用于凸集,凸集中只有唯一的本地最优,也即为全局最优,那么本地最优的问题就得以避免;然而,目前观察表明样本空间对于坡度来说并不是凸集,存在多个本地最优,那么遇到非全局最优的本地优化就是难免的。
除此之外,另有一种小概率情况会带来较差的结果。如果通往一个本地最优点的 gradient 通道在球内,然而这个本地最优点本身却在球外,那么 PGD 会在半坡上遇到边界,从而连本地最优也无法达到。
**这两点意味着 PGD 的运行结果是较不稳定的,需要多次随机初始化,取最优的一次作为最终输出,而现实中也确实是这样做的。**
在 Mnist challenge 的榜上,排名很高的 PGD 使用了50次随机初始化,并且发布 PGD 攻击的论文里似乎也是直接将多次随机初始化的过程作为 PGD 攻击算法必要的一部分,没有随机初始化的版本叫做 Basic iterative method attack,BIM。这对 PGD 的最终性能并没有影响,但是所需的多次初始化对于训练时间而言显然是不利的。
更多可移步:
7 参考文献
[1]. TOMOCAT. (2019). 机器学习必知必会:牛顿法和拟牛顿法. 数据怪兽. 知乎: https://zhuanlan.zhihu.com/p/81623816
[2]. NirHeavenX. (2017). 最全的机器学习中的优化算法介绍. CSDN: https://blog.csdn.net/qsczse943062710/article/details/76763739
[3]. LLLiuye. (2018). 学习率(Learning rate)的理解以及如何调整学习率. 博客园: https://www.cnblogs.com/lliuye/p/9471231.html
[4]. 易水寒. (2018). 机器学习优化算法中梯度下降,牛顿法和拟牛顿法的优缺点详细介绍. 电子说: http://www.elecfans.com/d/722244.html
[5]. 蕉叉熵. (2018). 拟牛顿法(DFP、BFGS、L-BFGS). CSDN: https://blog.csdn.net/songbinxu/article/details/79677948
[6]. Utterly Bonkers. (2019). 关于PGD(映射式梯度下降)对抗训练的理解. CSDN: https://blog.csdn.net/Utterly_Bonkers/article/details/103711767 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2022-12-12 08:22
发表于 2022-12-12 08:22
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡