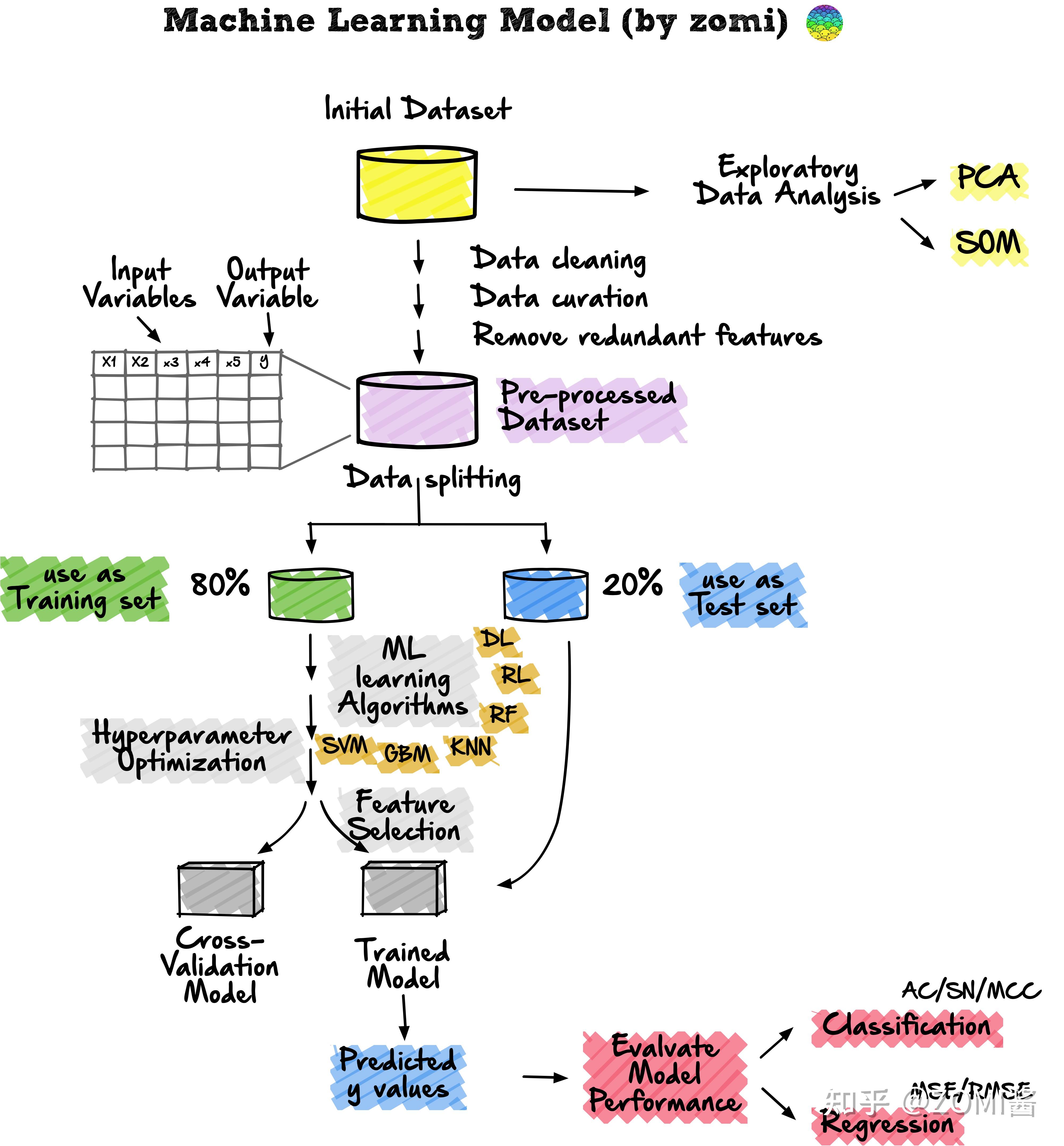
训练集 & 测试集
在机器学习模型的开发流程中,希望训练好的模型能在新的、未见过的数据上表现良好。为了模拟新的、未见过的数据,对可用数据进行数据分割,从而将已经处理好的数据集分割成2部分:训练集合测试集。
第一部分是较大的数据子集,用作训练集(如占原始数据的80%);第二部分通常是较小的子集,用作测试集(其余20%的数据)。
接下来,利用训练集建立预测模型,然后将这种训练好的模型应用于测试集(即作为新的、未见过的数据)上进行预测。根据模型在测试集上的表现来选择最佳模型,为了获得最佳模型,还可以进行超参数优化。
训练集 & 验证集 & 测试集
另一种常见的数据分割方法是将数据分割成3部分:1)训练集,2)验证集和3)测试集。
训练集用于建立预测模型,同时对验证集进行评估,据此进行预测,可以进行模型调优(如超参数优化),并根据验证集的结果选择性能最好的模型。
验证集的操作方式跟训练集类似。不过值得注意的是,测试集不参与机器学习模型的建立和准备,是机器学习模型训练过程中单独留出的样本集,用于调整模型的超参数和对模型的能力进行初步评估。通常边训练边验证,这里的验证就是用验证集来检验模型的初步效果。

 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2022-1-16 10:42
发表于 2022-1-16 10:42
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡