|
|
参考学习:Document
本文大概介绍一下python写入pb序列化的数据到Kafka,然后java这边在flink的基础上进行消费Kafka的数据。
先启动zk,然后启动Kafka。zk 3.4.8 kafka 2.4.1
我当时没配环境变量,所以都是切到相应目录去运行,有利于熟悉。
cd /Users/hebingrong/application/zookeeper-3.4.8/bin
./zkServer.sh start
zk占用了2181端口
https://blog.csdn.net/weixin_40283268/article/details/108722 FAILED TO WRITE PID 因为创建里面的tempdir时出现问题,修改一下这个临时目录的路径即可
启动成功后,jps 可以查看 QuorumPeerMain 进程。
cd /Users/hebingrong/application/kafka_2.13-2.4.1/bin
./kafka-server-start.sh /Users/hebingrong/application/kafka_2.13-2.4.1/config/server.properties
kafka使用了9092端口 启动完成后可以jps 看到 Kafka 进程
此时有

这三个进程。
然后是python写入pb序列化的数据到Kafka。
先准备pb的编译器,即 protoc。 这个推荐可以使用brew安装,我这安装的是3.6版本。brew 不方便安装一些历史版本的软件,所以要选定版本的时候我一般手动安装,brew维护的旧版本的软件太少了。
echo 'export PATH="/usr/local/opt/protobuf@3.6/bin:$PATH"' >> /Users/hebingrong/.bash_profile
快速导入环境变量,不过还是得定位到文件source一下。
接着是准备pb的原始对象文件。
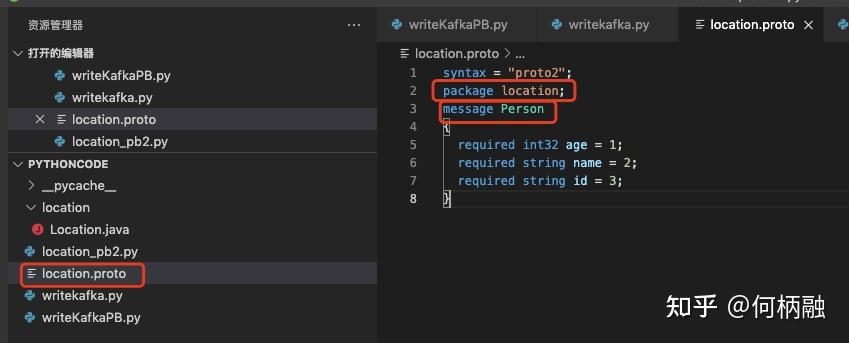
注意这里的三个名字,包名,文件名,message名,在python中不咋看得出来有啥用。
先提前看Java里面的认识一下
外部包名,类名,静态内部类的类名。 这里的message其实就是对应我们平常的pojo,也就是我们平常存数据的类。
这样我们就知道怎么填对应的属性了。还有required,optional修饰符。
required:一个格式良好的消息一定要(至少)含有1个这种字段,表示该值是必须要设置的;(也就是传输过程中如果没有这个值,那么就肯定失败)
optional:每个消息中可以包含0个或多个optional类型的字段。
repeated:在一个格式良好的消息中,这种字段可以重复任意多次(包括0次)。重复的值的顺序会被保留,表示该值可以重复,相当于java中的List,golang中的切片。
————————————————
版权声明:本文为CSDN博主「love666666shen」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:Mac端安装protobuf及其简单使用_sym的博客-CSDN博客_mac protoc
然后就是根据那个基本文件生成在不同语言当中的基本类。
protoc --python_out=./ ./location.proto
接着python还要安装Kafka的客户端。注意一下对应Kafka的版本即可。
python 安装pb支持包 pip3 install protobuf==3.6.1 python对应的pb版本也是3.6.1
import sys
import location_pb2
import json
from kafka import KafkaProducer
if __name__ == '__main__':
# object.id = "1"
# object.name = "张三"
# object.age= 18
# str_person=object.SerializeToString()
# print(str_person)
# object.ParseFromString(str_person)
producer = KafkaProducer(
# value_serializer=str.encode(), 我们调用SerializeToString就已经序列化好数据了,所以这里就不需要再定义序列化方式了
bootstrap_servers=['localhost:9092']
)
for i in range (10):
si=str(i)
object=location_pb2.Person()
object.id = si
object.name="张三"+si
object.age=18
str_person=object.SerializeToString()
print(str_person)
object.ParseFromString(str_person)
print("name="+object.name)
print(object)
producer.send('my_topic', str_person)
producer.close()这里就是连接到Kafka,然后推送到my_topic这个主题下。
location_pb2.person 就像是创建一个对象一样。
然后就是SerializeToString序列化 ParseFromString反序列化了。
接着就是flink这边去消费Kafka的信息。
基本结构如上
public class PBDeserializer implements DeserializationSchema<Person> {
@Override
public Person deserialize(byte[] bytes) throws IOException {
return Person.parseFrom(bytes);
}
@Override
public boolean isEndOfStream(Person o) {
return false;
}
@Override
public TypeInformation<Person> getProducedType() {
return TypeInformation.of(Person.class);
}
}
然后是主流程类
package com.hbr.readdata;
import location.Location.Person;
import location.PBDeserializer;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class FirstRead {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty(&#34;bootstrap.servers&#34;, &#34;localhost:9092&#34;);
// 下面这些次要参数
properties.setProperty(&#34;group.id&#34;, &#34;consumer-group&#34;);
properties.setProperty(&#34;key.deserializer&#34;, &#34;org.apache.kafka.common.serialization.StringDeserializer&#34;);
properties.setProperty(&#34;value.deserializer&#34;, &#34;org.apache.kafka.common.serialization.StringDeserializer&#34;);
//properties.setProperty(&#34;auto.offset.reset&#34;, &#34;latest&#34;); earliest
properties.setProperty(&#34;auto.offset.reset&#34;, &#34;earliest&#34;);
FlinkKafkaConsumer<Person> consumer = new FlinkKafkaConsumer<>(&#34;my_topic&#34;, new PBDeserializer(), properties);
// flink添加外部数据源
DataStream<Person> dataStream = env.addSource(consumer);
// 打印输出 对中文输出不友好,懒得去理这个自己得打印方式了
dataStream.print();
//先执行print,然后再执行这个mapfunction
dataStream.map(new MyMapFunction());
env.execute();
}
public static class MyMapFunction implements MapFunction<Person,String> {
@Override
public String map(Person person) throws Exception {
System.out.println(&#34;my name is &#34;+person.getName());
System.out.println(&#34;my age is &#34;+person.getAge());
System.out.println(&#34;my id is &#34;+person.getId());
return null;
}
}
}
接着注意依赖:
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.11.0</flink.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>pb反序列化这个类依赖于flink-core这个包,它是在flink-client这个依赖当中。
protoc生成的Java 基本类依赖于 protobuf-java 这个jar包。
基本的执行环境这些,比如 StreamExecutionEnvironment 这些,是在flink-streaming-java包,也是在flink-client包中。
然后flinkcustomer这个类,在flink-connector-kafka_2.11 即flink连接kafka的包中。
所以这里只引入了三个jar包,flink版本是1.11.0
然后对主流程类进行大改解析
&#34;auto.offset.reset&#34;, &#34;earliest&#34; 消费者还没启动时,生产者就把数据放到Kafka上,设置成这个之后,消费者启动的时候,还可以消费掉之前存储在Kafka上的数据。
&#34;auto.offset.reset&#34;, &#34;latest 这个就不能消费之前留存的数据,只能消费到之后发送到Kafka上的数据。
execute之后才是真正把任务提交给flink执行。
最后的截图如下:
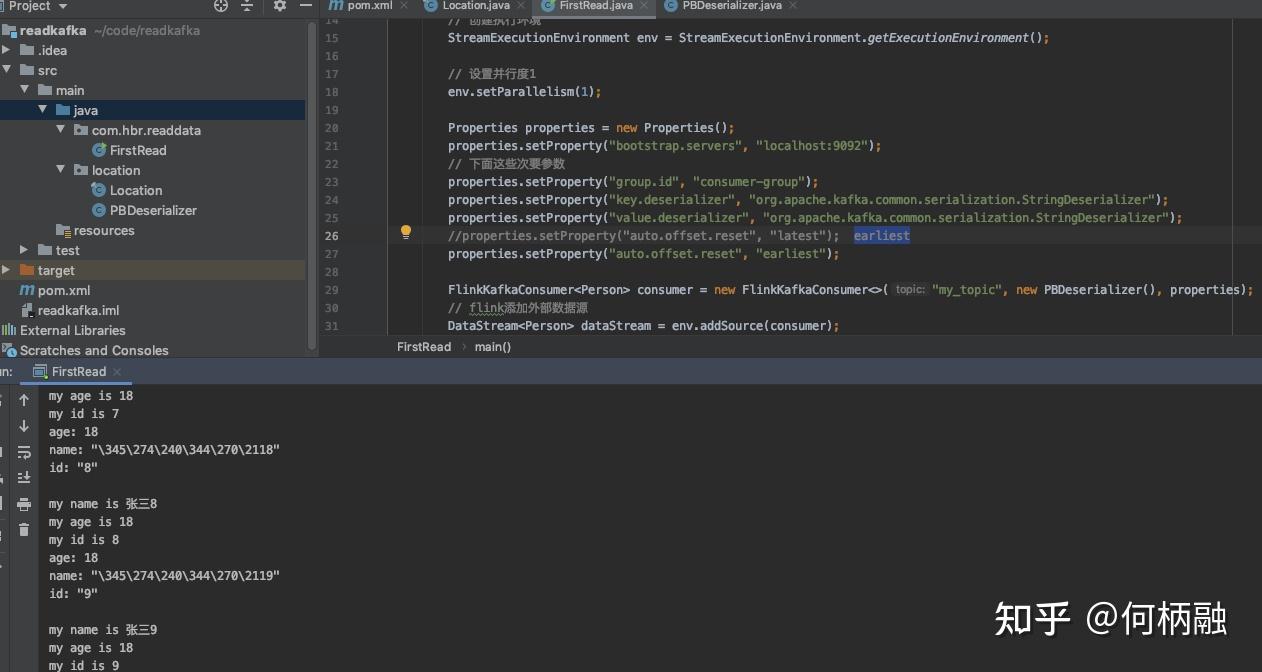
大概先这样。 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2023-2-21 08:12
发表于 2023-2-21 08:12
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡