|
|
初衷
metahuman的呈现效果非常好,但是查了很多教程,对它的表情驱动基本都是用iphone的livelinkface来实时的面捕驱动。
但是我们的场景是希望能够通过程序来驱动metahuman的表情动作,所以就需要自建一个数据源。Python并不是唯一的选择,不过平时用的最多,实现也比较快。
1. 本方案适用范围:
- 需要通过自己的数据源向Unreal发送实时数据的场景;
- 不限于Python,实际上任何语音都可以,只要支持socket通信即可。
2. LiveLinkFace解析
在B站上面查LiveLinkFace会查到非常多的metahuman的驱动视频,就不赘述了。关键在于我们希望能够模拟LiveLinkFace做一个数据源,这样就可以直接使用Unreal的官方插件,不用自己手工搭建一个livelink的数据源了。
iphone上面的界面如下,可以看到一共有61个表情控制参数。
LiveLinkFace的数据发送使用的未加密的Socket数据传输,故在PC上面做一个Socket数据的接收器就可以获取到帧:
import socket
cli = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
cli.bind(("127.0.0.1", 11111)) # 这里对应的是本机IP和端口,这里要和LiveLinkFace对应
data = cli.recv(4096)
with open('save.txt', 'wb') as fo:
fo.write(data)2.1 有表情数据时的数据格式
打开保存文件可以看到一帧数据如下,共:
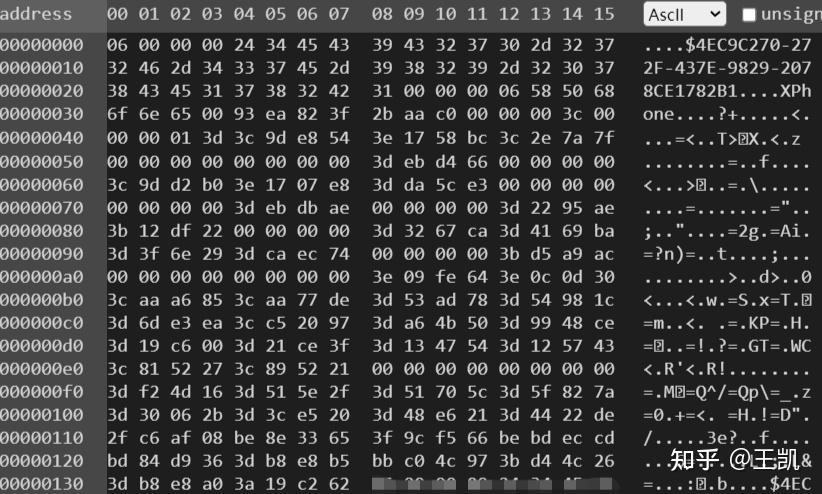
格式解析:
- 06 00 00 00 : 帧头
- 接着的37个字节:应该是设备号,每帧都是一样的
- 00 00 00 06:分隔符
- 接着的6个字节:设备名称,这个长度应该是可变的
- 00:考虑到设备名称可变,那么在后面肯定需要有分隔符,通过序列分析,分隔符为1个字节
- 接下来3个字节:应该是帧的ID,每帧+1
- 接下来4个字节:从0~1循环的32位浮点数,物理含义看起来是按照每10秒进行循环
- 00 00 00 3c 00: 分隔符
- 00 00 01 3d:常量
- 剩下的就是实际数据, 共244字节,float32
2.2 无表情数据时的数据格式
如果未检测到人脸的话,同样也有socket包,但其中没有表情数据:
3. 模拟数据源
模拟数据源需要注意以下几点:
1) 可以同时模拟多个设备同时发送,但是设备名称和设备号不能一样,不然会导致数据传输冲突;
2) 每两帧之间的发送间隔尽可能短(一般不超过50ms),否则会导致连接中断。
生成数据分为2个部分,分别是命令字head,和表情数据content,按照上面的规则合成一帧数据后,则可进行发送。
cli = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
ipaddress = (dst_ipaddr, dst_port)
while True:
head = ... # head的大部分内容都是不变的,只有4个字节的时间计数需要随时间变化
content = ... # 使用自己的数据
cli.sendto(head+content, ipaddress)4. 最终效果
https://www.zhihu.com/video/1496059958277529600 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2022-4-23 07:51
发表于 2022-4-23 07:51
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡